
数年前に比べると、深層学習による成果を見聞きしても驚かなくなったということはありませんか? 深層学習の各産業での応用や社会実装は、いよいよこれからが本番だと思うものの、2010年代半ばに次々と出てきた深層学習の成果を初めて見たときほどの驚きは、少なくとも私にはなくなってきていました。恐らく日々出てくる研究成果を追いかける専門性がないからだろうと思います。
しかし、例外はもちろんあります。例えば、OpenAIが発表した成果です。
1つは人間が書いたような自然な文章を生成することで昨年(2020年)の夏に各方面に衝撃を与えた言語モデル「GTP-3」、もう1つは、その画像版である「DALL・E」(ダリ)です。ダリを開発したのは米国の研究開発企業OpenAIで、2020年1月5日にブログで発表しています。
シュールレアリスムを代表する画家の1人であるサルバドール・ダリ(と映画WALL-E)にちなんで命名されこの画像生成モデルは、単に「赤い三角形を描いて」という程度のことではなく、「チュチュ(スカート)を履いた赤ちゃん大根が犬の散歩をしているイラスト」という短いテキストから、まるで人間のイラストレーターが描くように何種類ものイラストを生成するのです。
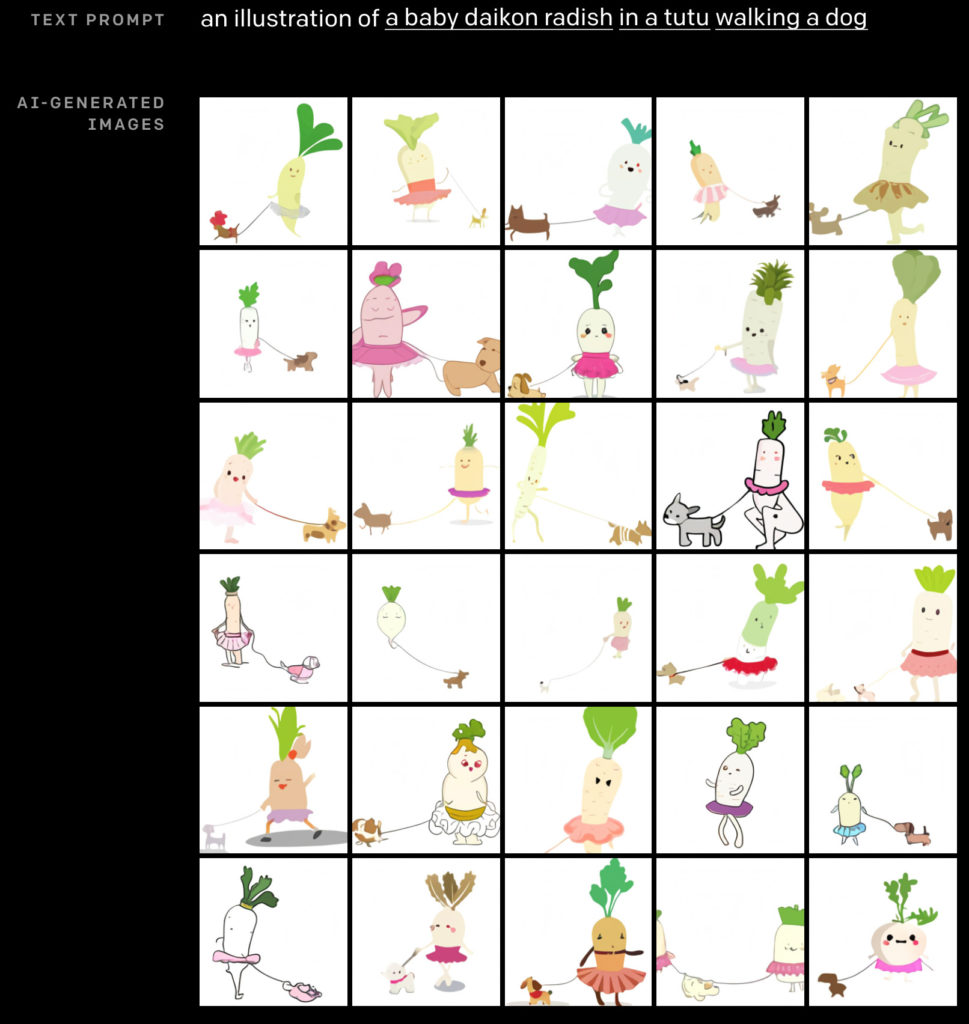
「赤ちゃん大根」(a baby daikon radish)と聞けば2通りの解釈があるはずです。1つは5〜10センチに成長した農作物としての大根。もう1つは上のイラストのように擬人化した大根で、しかも赤ちゃんであるようなキャラクターです。「チュチュを履いて犬を散歩させている」ということから、ダリというAIは大根を擬人化しているというのです。
「それっぽい」程度ではなく、創造的な生成
将棋や囲碁の最先端のAIが繰り出す一手は、ときどき人間のトッププロが困惑するようなものがあると言います。意図が分からず、何かのミスに思える不気味な一手です。ところが、後々その手筋の全容と合理性が分かると、人間のプロたちが知らなかった戦術があったことに驚き、そこに創造性を感じずにいられないと言います。
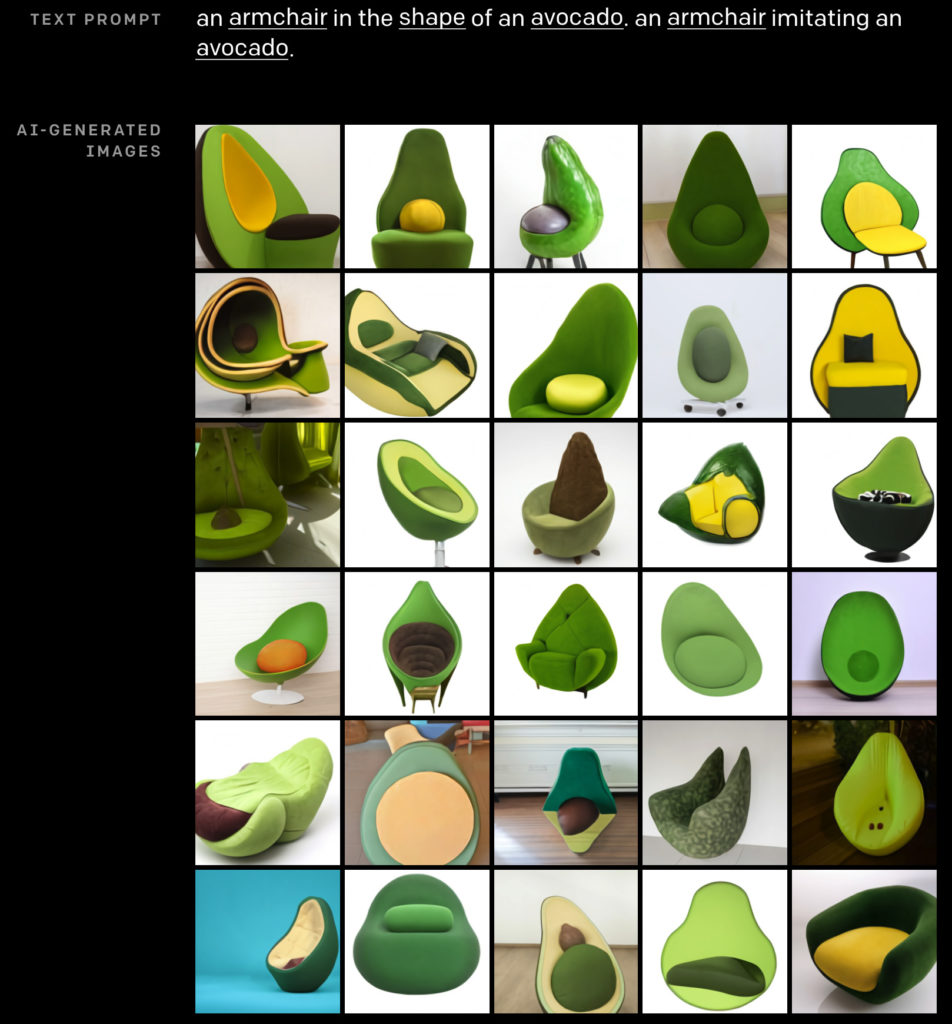
私は将棋も囲碁もやらないので、そうした創造性のある一手に感動することはできません。しかし、ダリが生成した以下の「アボカドの形をした肘掛け椅子」のイラストレーションの数々に創造性の萌芽を見出すのは私だけでしょうか?
すぐに実社会での応用も想像できそうな画像生成も
「店舗正面にopenaiという文字があるもの」というテキストから生成された以下の画像群を見ると、産業的な応用も思い浮かびます。

文字列の与え方によって生成される写真のリアルさに違いはあるものの、私が驚いたのは、店の構えや雰囲気に合わせたフォントやデザインを生成しているところです。それは「店舗正面」を「ポテトチップスの袋」に変えた同一タスクの生成画像を見れば、もっとはっきり分かります。私の目には以下の画像の6割ぐらいは、少し変な感じがしますが、2列め中央の袋などは、色といい、フォントといい、いかにも実在しそうな感じがします。袋の曲面に沿って文字を適切に歪ませていることも分かります。

産業的な応用を思わせるという意味では、マネキンにさまざまな服を着せた画像や、ベッドルームの調度品の種類や色を変えてバリエーションを生成した以下の画像なども驚異的です。解説を良く読むと「ベッド脇に水槽がある」という指示だけであるのに、ダリは、その水槽をベッドサイドテーブルの上に置くという意思決定(?)のようなこともしている、というのです。たくさんの画像と、その説明文を学習させれば、それが普通のことだと……、学習するのでしょう。

よくよく見るとリアリティーに欠けたヘンテコな画像もありますが、これらはダリが生成した画像から良いものだけを都合よく抜き出したものというわけではないそうです。
指示や図から正答を推論する知性も感じられる
ここまでの例だけでも私は繰り返し驚いたのですが、ダリが発揮したという推論能力にも、私は衝撃を受けました。
GTP-3では「これは『公園で犬を散歩している人』をフランス語に翻訳した文です」(here is the sentence ‘a person walking his dog in the park’ translated into French)と英語で入力すると、正しく「un homme qui promène son chien dans le parc.」とフランス語に翻訳するといい、これは指示を解釈しているように見えます。何をすべきか明示的に学習させたわけではないのに、正しくタスクを推論しているように見えます。OpenAIでは、これを「Zero-shot reasoning」と呼んでいるそうです(コンピュータービジョンや自然言語処理の世界で、明示的に学習させていない対象物を認識する「Zero-shot learning」という用語が使われていたことからの命名でしょうか)。
ダリも同様に、初めて与えられた指示を解釈して正しい画像を生成します。例えば、「同じ猫で、上は実写、下はイラスト」というテキストとともに1枚の猫の画像をダリに入力すると、以下のような画像が生成されたといいます。これは単にイラストを生成しただけでなく、自然言語の指示を理解したかのように感じられます。

ダリが部分的に正答したという図形を使ったIQテストの結果も驚きです。OpenAIのチームが使ったのはサイコメトリクスの世界で長らく使われているJohn Raven’s Matricesという3×3に並んだ図形から、右下の欠けている図形が何であるべきかを推論するテストです。例えば以下の問題なら、右下に入る正解の図形は「田」になります。

上の例は規則性から自明ですが、以下のようにけっこう難しい問題もあります。この問題セットでダリが正答しているのは1つだけではないかと思います。例えば下段左から2番めでいえば、これは円の外側がプラス、内側がマイナスの演算になっています。だから右下の正解は外側に2つの出っ張りがあるはずですが、ダリは内外とも出っ張りのない丸を示しています。(人間の感じる正解からすれば)不正解ですが、自然な描画です。
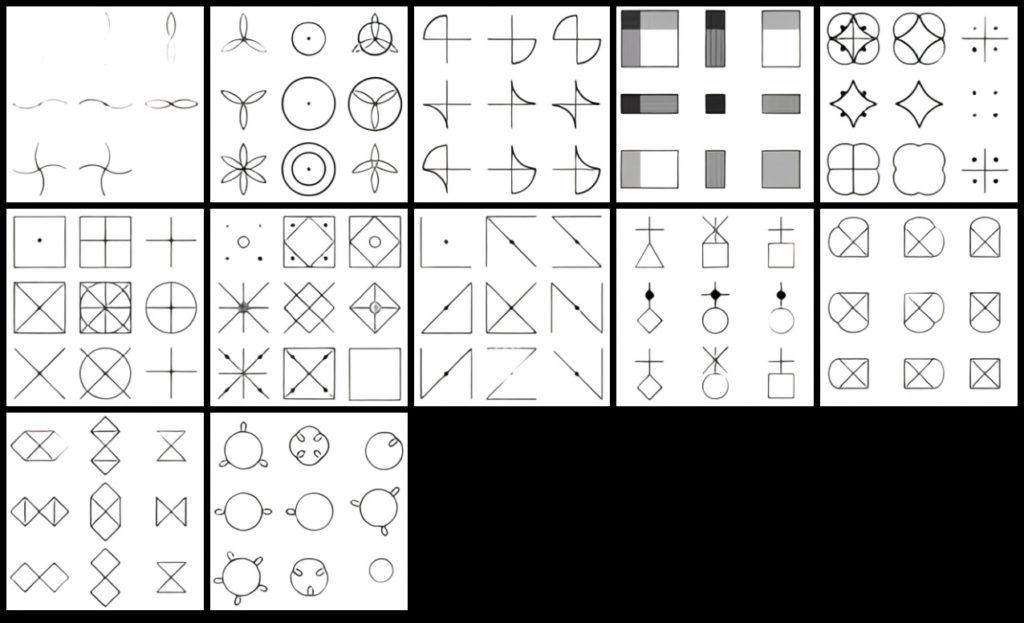
人間の認知能力には、空間把握、数的能力、推論、短期記憶など、いくつか異なる次元があると言われています。ただ、これらは相互に相関しているため、サイコメトリクスの研究者たちは「g-factor」と呼ぶ単一の尺度を使った一般知能の議論をしたりします。文化や言語の影響を受けずにg-factorを測定するのに適したIQテストの1つと言われているのがJohn Raven’s系のテストです。OpenAIの解説を読むと、図の置換や論理和や論理積といったブーリアン演算となっている問題にはダリも正答できるものの、それと違う上のような問題セットでは、ほとんど正答できていないとあります。だから「ダリは賢い」と形容するのは間違いだとは思いますが、それでも人間の一般認知能力を計測するテストを与えて正答することがあるという結果は興味深く、私は非常に驚きました。
推論ではなく知識という面では、もう人間が勝つ余地はないのかもしれないと思わせるのは、以下のような例です。「通り側から見た、サンフランシスコのアラモスクエアの夜の写真」という入力に対する画像です。実在しない建物や歩道、カフェが出てくるものの、Googleの画像検索で本物の写真を見れば、「そうそう、こんな感じ」と言わざるを得ないレベルで建物や風景を再現しています。単にサンフランシスコの一風景を写真のごとく再現できる、というだけではありません。学習させた、どんな街でも再現できるということですから、とっくに人間を超えているとも言えるのではないでしょうか。

以下は「中国の食べ物の写真」です。こちらはよくよく見ると、少しずつ変な感じもします。

何に応用できるか? あるいは応用は危険なのか
ダリも、その言語モデル版とも言えるGTP-3も「Transformer」と呼ばれる2017年に登場した深層学習の新しいアプローチを採用しています。従来のRNNやCNNといったニューラルネットワークを使った深層学習との違いや特性については、日本語で読めるこのブログが詳しいですが、精度が高くて並列処理可能、そしてデータ量が増えても計算量が定数時間に収まるという優れた特徴がTransformerにはあると言います。
Coral Insightsをご覧の皆さまならご存じかと思いますが、今回の研究成果を発表したOpenAIは、2015年にテック系起業家のイーロン・マスクやサム・アルトマンらによって設立されました。強力すぎる人工知能は人類の生存に対する脅威となり得るとの懸念から非営利組織としてスタートしています。今回の研究成果は同じOpenAI傘下の営利組織OpenAI Inc.によるものですが、その成果物が利用可能な形で出てくるかは分かりません。GTP-3に関しては、OpenAIがマイクロソフトに排他的ライセンスを提供したことで批判的に見る論調も昨年秋ごろから広がっています。産業上の利用価値が大きいからOpenAI存続のためのマネタイズということなのか、強力すぎるAIを一定の管理下に置きたいということなのか、意図は分かりません。ただ、多くの新技術同様に、いずれ数年もすれば民主化して起業家の手に渡ることになるのではないかと思います。そういう意味でも、スタートアップの起業家の皆さんには、インタラクティブに文字列を変更しながら生成画像を見ることができるOpenAIのオリジナルのブログを見ておくことをお勧めします。
Partner @ Coral Capital





