






「Legalscapeは一言でいえば『法律版のGoogle』です」。Legalscapeの八木田樹さん(Co-Founder&CEO)はそう説明します。Googleのミッションは「世界中の情報を整理し、世界中の人々がアクセスして使えるようにすること」ですが、Legalscapeはその一部である法情報を整理し、アクセスして使えるようにしようとしています。
Legalscapeは、弁護士事務所や企業法務部などで働く法律のプロに向けたB2Bサービスです。ベータ版サービスとして1年半ほど運営した後、2021年6月にLegalscapeの正式版がリリースされました。

Legalscapeの八木田樹さん
「法律版のGoogle」を目指すLegalscapeは、法律を扱うテクノロジー・スタートアップ、いわゆるLegalTechの1社です。しかし他のLegalTechとは違う野望を持っています。
「LegalTechのスタートアップでよく見るビジネスは、契約書を扱うサービスです。締結前契約書のレビュー、締結後の契約書管理、それに電子契約などです」と八木田さんは言います。電子契約の利用範囲は広がりつつあり重要な分野ではあります。しかしLegalscapeはもう少し遠いところを目指しているようです。
「私たちは、契約書とは違う領域で、法律関連の情報そのものの取り扱いに、真っ向から挑戦しています。契約書のような法的な文書を書く場合、弁護士や企業法務部の人のような法律の専門家にとってリーガル情報(法律関連の情報)の参照は非常に重要です。従来は主に紙の資料やPDFで参照していたリーガル情報を、Web上で簡単にリサーチできるサービスを作っています」(八木田さん)
プロの法律家が法的な文書情報を探す場合、従来は記憶とカンでアタリを付けてページをめくったり、紙の書類から探していました。それをデジタル技術で検索できるようにし、さらに機械処理もできるようにする——。これにより、弁護士や裁判官などの法律家や、立法や行政に関わる国家公務員の仕事を大幅に改善できます。さらには、法の運用の現場にもデジタル技術による変革を起こせるはずです。
Legalscapeは、国家の最重要インフラの1つ「法」のDX(デジタル変革)を、根底から進めようとしているわけです。
政府の判決データベース計画に技術を提供
Legalscapeの取り組みの1つに、政府主導の民事判決のオープンデータ化検討プロジェクトでの技術協力があります。現在、Web上で一般公開されている最高裁の判例データベースに収録されている判例は約6万件。実は、これは全体のほんの一部で「先例性の高い重要な判決書」だけが収録されています。一方、進行中のプロジェクトでは民事判決を全件データベース化することが目標です。
ここで問題となるのが、プライバシーです。これまでは、忙しい裁判官が判決書内の人名などの固有名詞を一つ一つ伏せ字に置き換える(仮名処理)ことで、一般公開がなされてきました。今後、年間数十万件とも言われる民事判決のすべてを利活用可能にするためには、これまでのような人手での仮名処理は困難です。
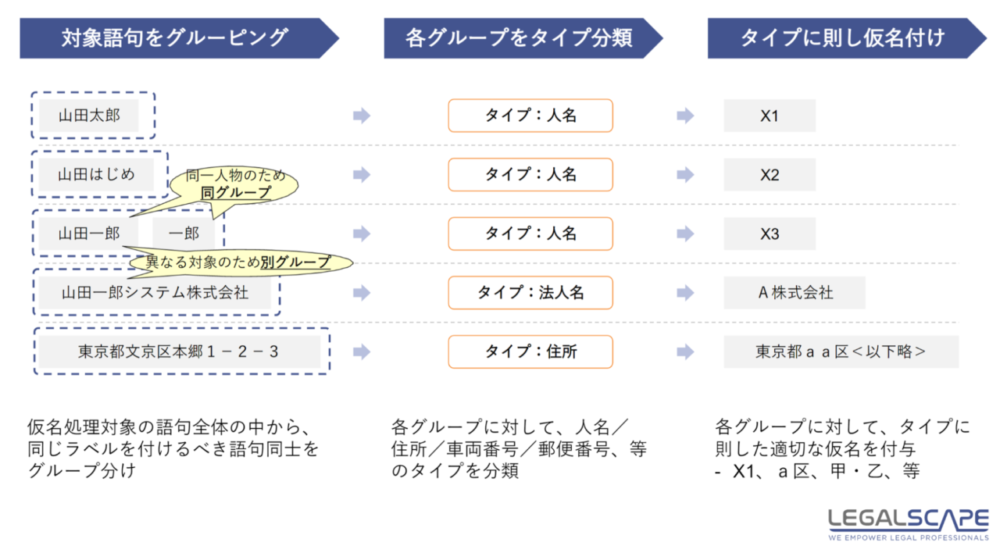
Legalscapeは、この問題を解決するため、日弁連、最高裁、法務省、内閣官房等が参加するプロジェクトチームに参加し、判決書を自動で仮名処理する技術の実証実験を行い、95%程度の精度を達成しています。また、残る5%の誤りを修正するための作業を効率化するツールの実証実験等も含め、スタートアップとしては異例ながら、日本初の判決全件公開にむけ、大きく寄与しています。
日本に住む私たち全員にとって従うべき「法」の一部なのに、判例などは簡単に閲覧することすらできない状況。Legalscapeは、持ち前の高い技術力を生かして、法律業界全体と協働しながら今後もオープンデータ化を進めていきたい、と八木田さんは話します。
参考記事:「民事判決のオープンデータ化」とは何で、なぜ必要で、なぜ私たちが関わっているのか|Legalscape
「PDFによる電子化」を超えて―構造化とリーガル・ウェブ化
紙の文書のオープンデータ化・デジタル化というとPDFを思い浮かべる人が多いかもしれませんが、Legalscapeが開発するのは、PDFや紙の情報を解析して構造化されたデータへ変換する技術です。それによって法情報の利活用を促進することを目指しています。
たとえば、判決書には判決の結論を書いた「主文」、それに続く「理由」など一定のフォーマットがあります。多数の判決が含まれるデータベースから主文だけを検索対象とするには、あらかじめどの部分が主文かを解析して、単なるテキストやレイアウトの情報ではなく、意味的な情報が含まれる形式、いわゆる構造化されたデジタルデータへと変換する必要があります。
Legalscapeは2018年頃、創業100年以上の法律出版社である第一法規(株)に、プレーンテキストの判決文を、自動で構造化する技術を提供。目次から判例の本文にアクセスできるようにしたり、検索キーワードが目次のどの箇所に含まれるかを表示するなどを可能にしました。このときには特許も取得しています。
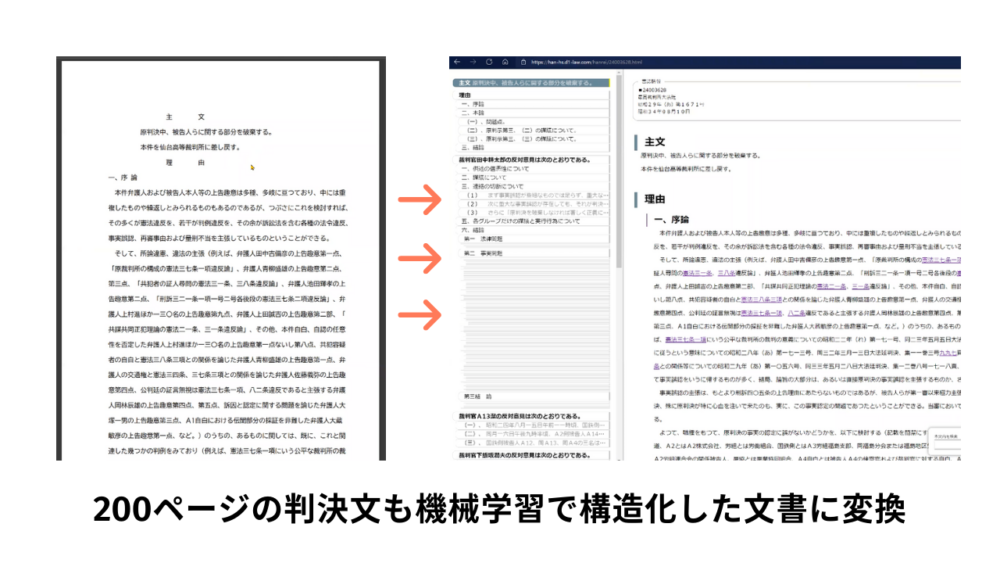
判決文(左)を機械学習を使って構造化した文書(右)に変換した例。特定の裁判官の意見がどこに書いてあるか、というのも一目瞭然
Legalscapeの八木田さんたちは、もともと判例の構造解析をしようと起業したわけではなかったものの、判決文の構造解析で技術力を蓄積。2019年からは、判決文だけではなく、法律の条文、法律関連書籍、パブリックコメントなど、広くリーガル文書を対象として構造化されたデジタルデータへとする技術を開発しました。
PDF書籍の章立ては人間には構造が自明ですが、コンピューター処理の面で考えると、全く事情が違います。レイアウト情報から構造を正しく推測する処理をソフトウェアでやらなくてはいけません。Legalscapeでは2019年からこの書籍PDFの章立て解析でも特許を取得しています。
ただデジタル化するだけでも検索可能になりますが、一歩進んで構造化データとし、さらに一歩進んでリーガル文書同士の参照関係の解析を行う(リーガル・ウェブ化、後述)ことで、Legalscapeは従来全く不可能だったリーガル文書の利活用ができるようになっています。
例えば、以下の画面のように目次情報から素早く文書中の必要な部分にアクセスできるようになっています。画面では「金融商品取引法」を「公開買付け」「公告」の2つのキーワードで検索していますが、左側の目次の横には青とオレンジで数字が表示されています。数字はキーワードの当該セクション中の個数を、また青色で一部のキーワード/オレンジ色ですべてのキーワードが当該セクション中に含まれることを示しています。
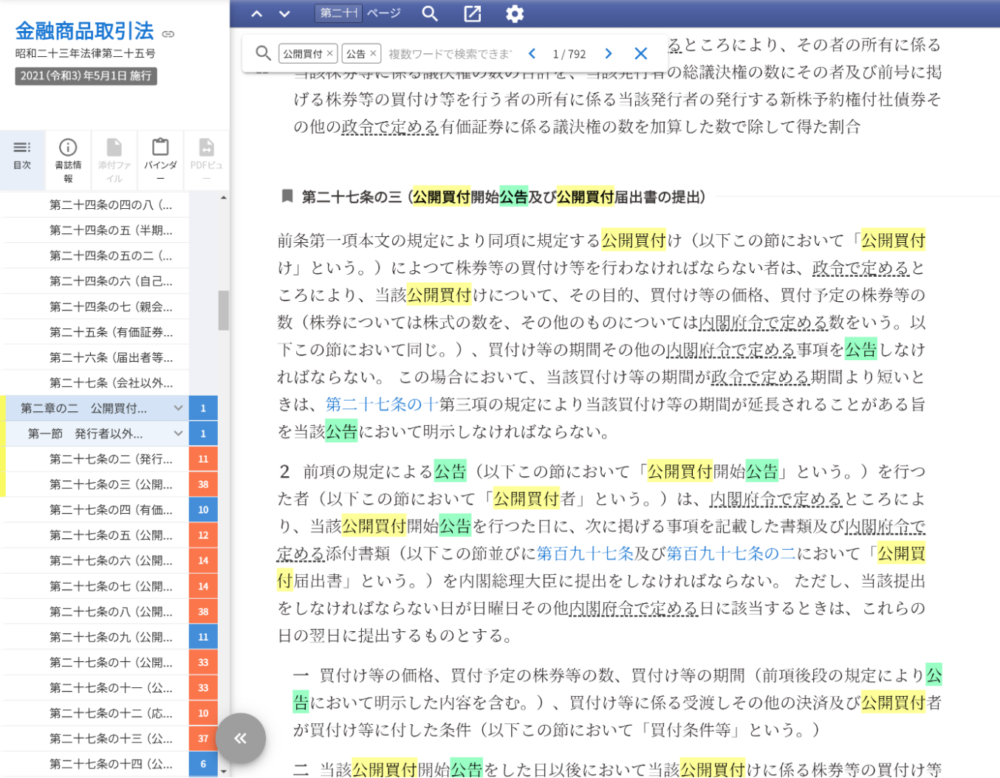
PDF文書などと違い複数単語による検索をした上で、構造化された目次・章に、何回当該検索語が登場しているかも青とオレンジの数字で分かりやすく表示することが可能
さらにLegalscapeのサービスで重要な機能は「逆引き」です。金融商品取引法の第27条の2について関連文献を調べたいとき、法律専門書やパブリックコメント、ガイドラインなどの他のリーガル文書の中で「金商法第27条の2を参照している部分」を一覧できるのです。
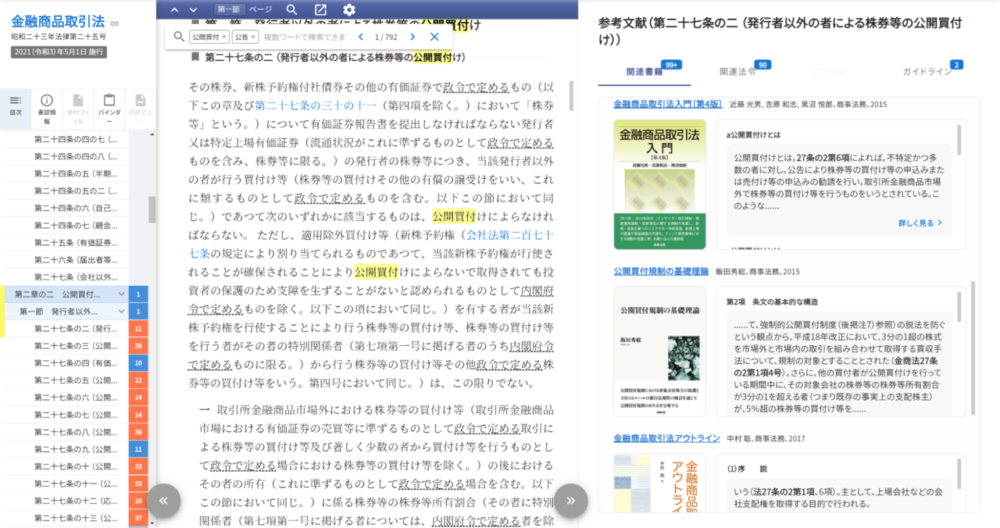
法律の条文から、それに言及する書籍の解説を簡単に参照できる
「法律の世界では、ある文献だけでなく、その文書を参照・引用している別の文献を読む必要が出てくる場合があります。例えば金商法の場合は法案の立案担当である松尾直彦先生の書いた『金融商品取引法』という本を読んだり、その法改正がなされた際のパブリックコメントを読む必要が出てくる場合があります」と八木田さんは言います。こうした、法律家ならではの情報ニーズに対して、きめ細かなサービスを構築して提供することがLegalscapeの大きな特徴です。
こうした高度な検索機能により、従来2時間かかった法律文書のリサーチが5〜10分で済むようになった事例もあるといいます。法律に関わる仕事の現場で、Google検索のようなイノベーションが現在進行形で起きているわけです。
現在、Legalscapeのサービスで参照、検索できる法律情報は、8出版社950冊以上の書籍、法令7,000種以上、パブコメ約2万件(全件)、ガイドライン300件以上に及びます。

10年先の国家インフラを見据え開発チームを増強
そんなLegalscapeの今の課題は——、これは多くのスタートアップに共通する課題ですが——開発チームの増強です。インタビュー時点の開発チームはCTOを含め5人体制。「もっと機能を開発していきたいが、なかなか手が回らない」と八木田さんは言います。
エンジニアにとって、「どのようなビジョンを持つ会社なのか」は大事なところでしょう。Legalscapeのビジョンは、主に3点です。
(1) 法情報を誰にとっても利用可能にする(法情報のオープンデータ化)
(2) 法情報を整理する(リーガル・ウェブ化)
(3) 法の「メンテナンス」に寄与する(「法のインフラ」化)
このうち、(1)は前述の判例データベースなどの取り組みを指します。(2)は前述の法令や書籍などの構造化と、相互リンクの付与です。そして(3)は、さらに遠いところにある目標です。
(2)で「リーガル・ウェブ」という耳慣れない用語が出てきていますが、実はすでに米国では構造化された法律文書がネットワークのように相互参照する状態が実現されつつあります。以下の画面は米Casetextという2013年創業のLegalTechスタートアップで「Johnson v. U.S.」の判例を検索した例ですが、この判例を引用した他の法律文書が表示されています。
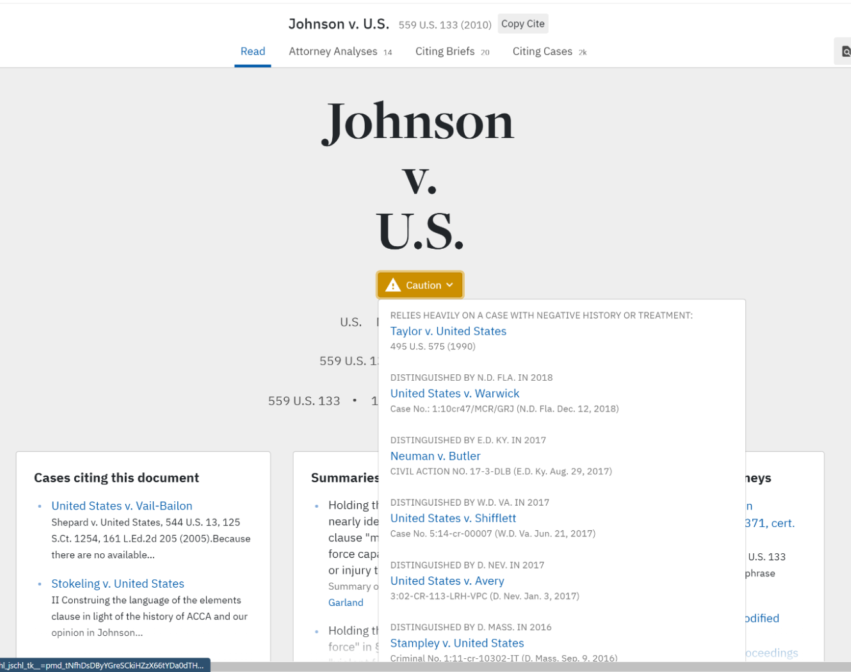
米Casetextによる判例の表示例。当該判例を参照している関連文書も表示されているほか、その参照が否定的な文脈であるかなども表示される
特定の判例データそのものをいくら解析しても、その判例に言及している文書のことは分かりません。こうした「逆引き参照」が可能なのは、関連する法律文書群を構造的にデジタル化して参照情報を取り扱っているからです。これがLegalscapeが目指す「リーガル・ウェブ」の世界観です。ただ法律文書をPDFとして「文書内」を検索可能にすることや、紙を持ち歩かなくて済むという「デジタル化」ではなく、さらに先の世界を見据えているわけです。
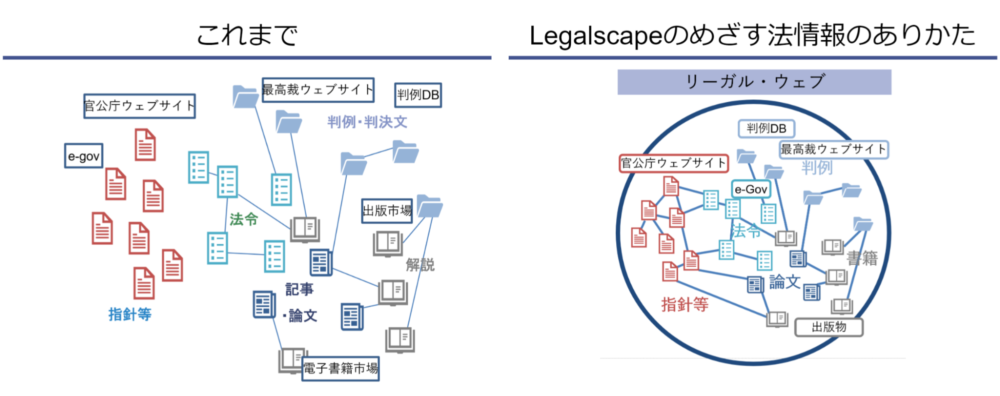
法律情報はもともと文書同士が相互に参照した状態になっています。ただ、紙の書類の時代には、大量に関連文書を読み込んだり、その領域のエキスパートにならなければ、逆引き参照に相当するリサーチはできませんでした。それがリーガル・ウェブが実現した世界では、法情報の全てのエンドユーザーにとって、しかもより短時間に可能になるということで、これこそLegalscapeが生み出そうとしている本質的価値です。これはGoogleがネット全体をインデックス化して何でも検索できるようにしたのと同じような法文書のイノベーションです。
さらに八木田さんらが見る将来のビジョンは、法の「メンテナンス」を、人手からデジタル技術に一部置き換えることです。現時点では前述の法令、パブコメ、法律書籍などは人手でメンテナンスされています。たとえば、法令の改正は、各省庁で従来の法令に対する「改め文」の固まりの形で作成し、官報で公布されます。それを法律出版社が手で作業をし、法令DBとして販売し、各省庁が購入しているのです。多くは人手で、ほとんど自動化されていません。また法律書籍も法令改正とともに改定されますが、これも編集者が一字一句人手で修正しています。
こう聞けば、エンジニアやテクノロジースタートアップの皆さんにはすぐ分かるでしょうが、現状の「法のメンテナンス」のやり方には大きな課題があります。人手なので手間がかかり、そして人手なので「間違える」ことです。実際、最近は法案の文面の間違いと訂正が相次ぎ、国会で問題視される出来事が起きました。
エンジニア目線で見るなら、このような課題に対してはGitHubのような仕組みや、「リーガル・ウェブ」による文献同士の関係性ネットワークの構築が解決策となります。ただし、そのための法整備、合意形成、そして実装への落とし込みとなると、誰にでも手を出せる仕事ではありません。LegalTechというだけでなく、GovTechの側面がある領域といえます。
Legalscapeは、政府プロジェクトへの協力や、法律出版社との関係構築などを進めることによって、「法のインフラ構築のデジタル化に取り組めるポジション」にいるGovTech企業でもあるわけです。
八木田さんは、「法のインフラのデジタル化には10年かかるかもしれないし、30年かかってもやることが残っているかもしれない」と言います。取り組むべき課題は尽きません。やるべきこと、すなわちビジネスチャンスと開発すべき機能はたくさんあるわけです。
Legalscapeの野望はまだあります。法情報のデジタル化が進めば、デジタルならではの新たな付加価値を創出できます。「現状の法情報を整理して、参照関係などを全部整理すると、新たに法改正するとき結論に矛盾しないようにチェックするといった、意味的な部分に踏み込むことができるようになるかもしれません」と八木田さんは説明します。
法のメンテナンスがデジタル化されたなら、法に関わるすべての人の働き方が抜本的に変わります。また機械処理による新たな可能性も生まれ、一般の人にとっても良い影響があるかもしれません。例えば、大量の判決文をAIが統計的に解析し、法的安定性(同じような事件で同じような判決になること)に寄与しつつ、事件に直面した一般の人にAIがアドバイスすることができるかもしれません。
米国では20年前からLegalTechが台頭し、多くの蓄積があります。一方、日本のLegalTechはまだ始まったばかり。自然言語処理や文書処理、AIなどの新しい応用により、日本のLegalTechが新しい段階に入る可能性があります。Legalscapeというスタートアップは、今後10年、ひょっとすると30年続くLegalTechの取り組みで重要な足跡を残せる職場になるかもしれません。現在、エンジニアを中心に採用中とのことなので興味のある方は同社の採用情報をご覧ください。
※情報開示:LegalscapeはCoral Capitalの出資先企業です。
(取材・文/西村賢、星暁雄)
Editorial Team / 編集部






