






Coral Capitalのポッドキャストでは、かなりAIに編集作業を頼っています。英語でインタビューしていることから、日本語では未実現の最新技術を使ったサービスに触れる機会があるのですが、ここ1、2年は、その進化には目を見張るものがあります。
収録した音声を文字(テキスト)に変換する「文字起こし」の精度が上がった結果、もはや人間に依頼する意味はなくなりましたし、音声編集についても画期的な機能が登場しています。それは音声から文字起こしされたテキストを編集することで、それに対応する元の音声データも同時に編集可能である、という機能です。音声編集をテキストで行うことができるのです。
ちょっと信じられないことですが、テキストから一部を削除すると音声データから対応部分が削除されるばかりでなく、文字起こしされたテキストの一部、例えば「two dogs」を「three dogs」にキーボード入力を使ってタイプし直すと、その人の声で新しい単語の発話データが合成されて自然な形で音声データに挿入される、という機能があったりします。発話者の声は事前に決められた文章を読んで学習させる必要があるものの、従来では考えられない魔法のような技術が数ドルの利用料で使えるところまで民主化してきているのです。
Coral Capitalのポッドキャストは日本語記事としても配信しています。英語テキストはDeepLを使って翻訳しているのですが、もはや下訳では人間の出番はありません。さすがに、当該領域に詳しいプロの翻訳者にDeepLはまだ勝てませんが、絶対に訳し漏れがないこととか、数字に間違いがないこと、何より1、2分で翻訳が終わることなど、人間による作業より安心・便利な面もあります。さらに、最近の大規模言語モデルの進化具合を見ていると、今後数年でより正しく文脈を理解し、専門領域の知識を踏まえた上で翻訳するようになることは間違いないように思えます。
DeepLで良くある誤訳は文法的には両義に取れるようなセンテンスについて、常識やコンテキストが分かっていないために起こるものが少なくありません。例えば「グーグルはモトローラを買収した。彼らが破綻していたからだ」というとき、この彼らが「モトローラ」であることは人間には自明ですが、文法的には「グーグル」とも取れます。なぜ自明かといえば、破綻した企業を別企業が買収することは良くありますが、その逆はないという常識があるからです。そもそもグーグルが破綻していないことは常識です。こうした知識を大規模なテキストデータを学習データとしてAIに獲得させる、というのが今まさに急速に起こっていることです。
この記事では、特に2022年4月にGoogleが発表したPaLMと呼ばれる大規模言語モデルの成果に触れつつ、こうした新技術の応用領域を垣間見させるスタートアップの事例を概観し、今後の応用可能性を考えてみたいと思います。
※上記の文例はコンピューターによる知識獲得の研究において、その性能・精度評価を行う文例セットの「Winograd Schema Challenge」の日本語版に関する研究論文「日本語Winograd Schema Challengeの構築と分析」から引用しています。
認識から生成、そして画像・音声から言語へも
神経科学にインスパイアされたニューラルネットワークの威力は破壊的で、特に画像や音声認識において目覚ましい成果を上げてきたことは周知の通りです。最近Coral Capitalでお話させていただく起業家の方の事業計画でも、ロボティクスや自動化の文脈では当たり前のように画像認識の話が出てきます。
一方、2014年にモントリオール大学で博士課程に在籍する学生だったIan Goodfellow氏らが研究を手がけた「Generative adversarial network」(GAN)の登場以降は、深層学習の応用として何かを認識する技術から、逆に画像や音楽、文章を生成する技術として応用される領域が花開きました。2017年にはGoogle BrainがTransformerと呼ばれる新しいモデルを発表し、そのTransformerを使った例としてOpenAIのGPT-2、GPT-3などが話題となりました。GTP-3を「テキストによる指示→イラスト生成」に応用したDALL・Eという研究成果については、以前Coral Insightsでも記事にしたことがあります。これはこれで衝撃的な成果なので、未見の方はぜひ「言葉の指示で高度なイラスト生成、新AI「ダリ」は起業家必見 | Coral Capital」をご覧ください。
大規模言語モデルの性能は2022年に入って人間の平均を超えた?
深層学習を応用した翻訳で実用レベルに達するのに必要だったのは、実は桁違いに多いデータ量だった、ということに似て、ここ数年は語同士の結びつきなどを統計的にデータ化した、いわゆる言語モデルの大規模化と、モデルそのものの進化が同時に起こっています。
Googleが2022年4月4日に発表した「Pathway Language Model」(PaLM)の成果に、私は衝撃を受けました。言語の理解や推論、常識による判断を試す一連のタスクにおいて、すでに平均的な人間の成績を超えた、というのです。
上に挙げたWinogradのテストをはじめ、常識・推論や文脈理解、文補完など英語圏のNLP研究(自然言語処理)で良く使われる評価用タスク29種類のうち28種において、GTP-3を含む、それまでの最新の大規模言語モデルの性能を上回ったばかりでなく、平均的な人間のスコアを超えているのです。しかも、規模拡大による精度向上は飽和しているように見えないのです。発表ブログには、以下のように書いてあります。
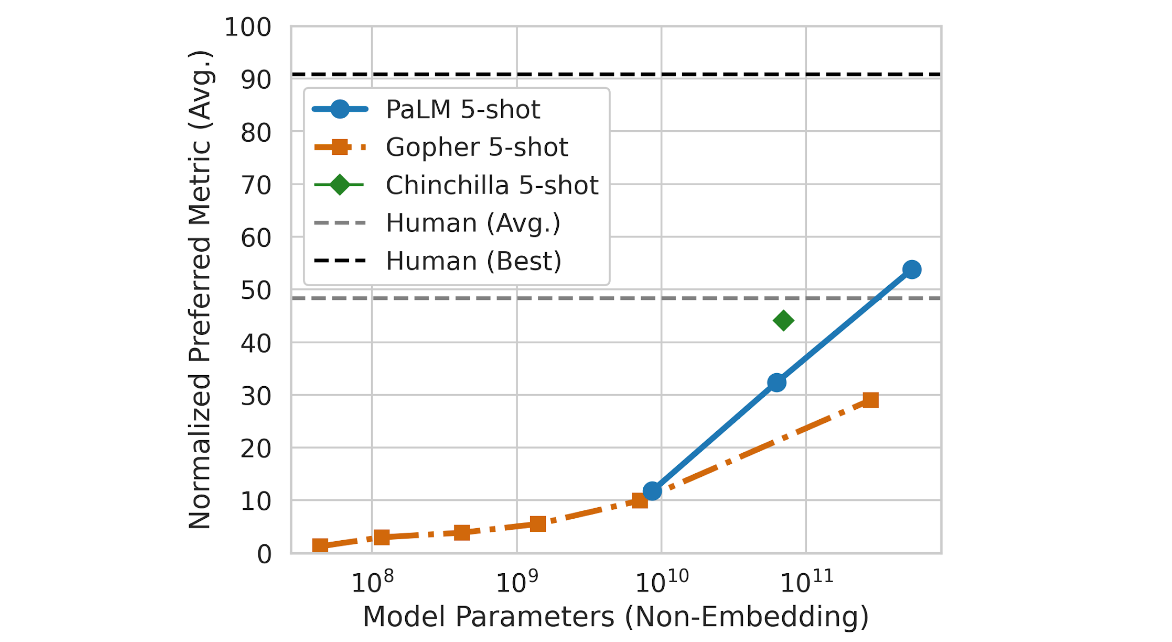
- Beyond the Imitation Game Benchmark(BIG-bench)という150種の推論テストのうち良く使われる58種のテストの平均スコアで比較したところ、その成績はデータ量に対して対数線形モデル的な伸びを示していて、まだ飽和していない(下の図の青い線)
- 従来知られているよりも遥かに多い5,400億パラメーターの言語モデルであるPaLMの成績は、平均的な人間の成績(下の図で灰色の水平の破線が人間の平均)を超えている
BIG-Benchにどんな推論が含まれているかは、GitHub上のこちらのリストを見れば、大体わかります。ちょっとだけ項目を日本語訳してみます。
- 説明文を読んで、もっとも適したことわざを選ぶ
- 与えられた主張の中に時代考証的におかしなものがあるか判定する
- 数少ない例文のペアから対象言語の文法や語彙を推論する
- 曖昧性の残る語彙やフレーズの使用について常識から意味を確定する
- 常識が適用できない空想の世界においてのみ成立する推論をする
- 特定の未来を予測するために、より詳細な付随質問文を生成する
- 人間の感覚器や臓器に関する質問に答える(例:匂いに関係する感覚器は?→鼻)
- 暗喩を理解する(例:彼は絶望の海に沈んだ→「絶望の海」は海ではなく、深い落胆のこと)
- 四則演算について回答する
- 物理の問題を解くために最適な方程式を選ぶ
- 文章にジェンダーバイアスがないか判定する
- シェイクスピアの戯曲において近くにある2つのセリフが同一人物によるものかどうか判定する
- 社会的文脈の知識が必要なダークなジョークの意図を理解する
曖昧な文でも常識や知識から判断して正しく意味を捉える
時代考証を判定する例では、例えば問題文として「米国上院議員がウェイド・デイビス法案成立に一票を投じた」というものがあります。英語では「her vote」となっていて、女性だと分かるのですが、この文は時代的におかしなことになっています。ウェイド・デイビス法案は南北戦争時代のことなので1864年成立とかなり昔のことであるのに対して、史上初の女性上院議員はそれより後のことだから、だそうです。
上の例は、日本人には馴染みが薄い話なので、常識というよりクイズ問題のように感じるかもしれません。でも例えば「その町奉行のお気に入りはラテだった」くらいだといかがでしょうか? あるいは「2003年に創業して、プロダクトを作る前に20億円を資金調達した」なら、どうでしょうか? 後者の例文はスタートアップ界隈の人であれば、すぐにあり得ないと思うはずです。例文が「2003年」ではなく「2021年」であればあり得ます。それは相場に関する知識があるから分かるわけですが、こうした「これは、おかしいな?」「ここはこういう事情のはずだから、発話者の意図はこうだろう」という推論能力は文章処理ではきわめて重要です。音声の文字起こしでAIが聞き取れないものを人間の私が聞き取れるのは、ITやビジネスのドメイン知識があるからです。例えば、SaaSで良く使われる指標のCACとLTVの関係性について話をしているときに「9倍」という数字が大きいか小さいか、また誰がどう感じてるかについての理解がなければ、それを論じている文章を正しく編集したり、翻訳するのは難しく、誤訳や間違った編集が起こってしまうのです。
だから、これまでは関連する業界知識がない人に翻訳や編集を任せられなかったわけですが、今や大規模言語モデルは、こうした知識を獲得し得るモデルに進化したのです。AIに膨大な文章を読ませれば、その中にはCACとLTVのあるべき比率の議論も出てくるでしょう。それが、たとえ学習データ全体の1兆分の1の割合でも、正しく学習してアウトプットに反映できるようになりつつある、というのが、最近の大規模言語モデルの進化のようなのです。BIG-Benchに含まれる「曖昧性の残る語彙やフレーズの使用について常識から意味を確定する」というタスクの例文を見ていると、現場の編集作業で必要とされている推論そのものだな、と思えます。
社会関係の常識も理解するのでジョークも分かる
もっと人間らしい文脈の理解の例として、以下のようなダークジョークの理解を問う問題もあります。
My wife left a note on the fridge that said, “This isn’t working.” I’m not sure what she’s talking about. I opened the fridge door and it’s working fine!
冷蔵庫の扉に妻が「This isn’t working」とメモを残し、夫のほうは「なんだよ冷蔵庫は壊れてないじゃないか?」と言う場面です。妻のメモは亀裂の入った夫婦関係のことを指していて「私たち、もうダメかもしれない」と言ってるわけですが、これが苦笑を誘うジョークであると理解できるかどうか、ということです。
以上のようにBIG-Benchは結構むずかしくて、平均的な人間のスコアが100点満点換算で50点というのも納得できます。
Googleの最新の大規模言語モデルであるPaLMはその人間の平均スコアを超えていて、しかも、もし学習時のパラメーター量を10倍、10倍としていけるのであれば、まだ線形にスコアが伸びるように思われるというのです。グラフを見れば分かりますが、PaLMのパラメーターの規模が100倍になれば「優秀な人間のスコア」(90点)を超えるのではないかと思わせる性能向上の推移となっています。
転移学習により少量の例からPythonコーディングも好成績
もちろん単純に言語モデルのパラメーター数を上げていけるわけでもなく、GTP-3にしてもPaLMにしても、その力技はビッグテックならでは、という印象です。2020年に話題になったGTP-3の1,750億パラメーターというのは、それ以前のMicrosoftのTuring NLGの100億パラメーターの17倍という規模でした。そして2022年4月に発表されたPaLMはGTP-3の約3倍となる5,400億パラメーターという規模。これは計6144チップにも及ぶ、GoogleのAI専用チップのクラスター「TPU v4 Pods」と並列処理によって達成できたものだといいます。
近年、言語モデルが大規模化した結果は、単純に獲得知識量が増えたということだけではなく、汎用性が高まったということでもあるようです。PaLMではわずかなPythonのコードが学習データに含まれていただけであるのに(PaLMが学習に使ったのは書籍やネット上の文書、Wikipedia、会話文、GitHubなど)、Pythonコードに特化して50倍の学習データからモデルを作った先行研究事例とコーディングタスクの成績で肩を並べたのだといいます。
これは、他のプログラミング言語や自然言語によって学習した知識が効率的にPythonコードの学習に転移するからで、そうした転移学習による効率化は大規模言語モデルの性質だとしてきた研究を裏付ける結果だとGoogleは説明しています。
以下は実際のPythonのコーディングタスクの例です。左側のコメントにあるのが仕様で、右側がPaLMが生成したコードです。

これは、とてもインパクトのある話ではないでしょうか? プログラミングは言語によって文法が違うものの、抽象度や利用目的が似ていれば、それほどコーディングのアプローチは変わりません。3つか4つのプログラミング言語を学んだことがあれば、全く初めての言語であっても少しの学習で上記のようなコードくらいは、どんな言語でも書けます。つまり、人間と同じように知識の汎化が起こっているのでしょう。だとすると、他の応用領域、例えば法律文書の理解や生成というタスクでも同様に、異なる種類・領域の契約書への対応が、少ないデータセットでできるようになる、ということではないでしょうか。
ここにはスタートアップがたくさん生まれてくる余地があるように思えますし、実際すでに大規模言語モデルを使ったサービスが出始めています。以下、大規模言語モデルを活用したスタートアップを眺めてみたいと思います。
Copy.aiはタイトルからブログ本文もSNS投稿コピーも生成してくれる
Copy.aiはGTP-3をベースにした文章生成サービスの2020年創業のスタートアップです。これまで$14mほどをSequoiaやTiger Globalから調達しています。Copy.aiで生成対象となるのは、SNSで使うデジタル広告やサイトのコピー、ブログのタイトルやアウトライン、本文、ECサイトの商品説明などです。フリーミアムモデルですが、現在有料プランは月額49ドルのもののみです。
実際にCopy.aiを使って「How Generative AI Is Transforming Businesses」という記事タイトルと、数個のキーワード(AI、GTP-3、neural networkなど)だけを入力して、ブログを自動生成してみたところ、かなり「読める」ものが出てきました。
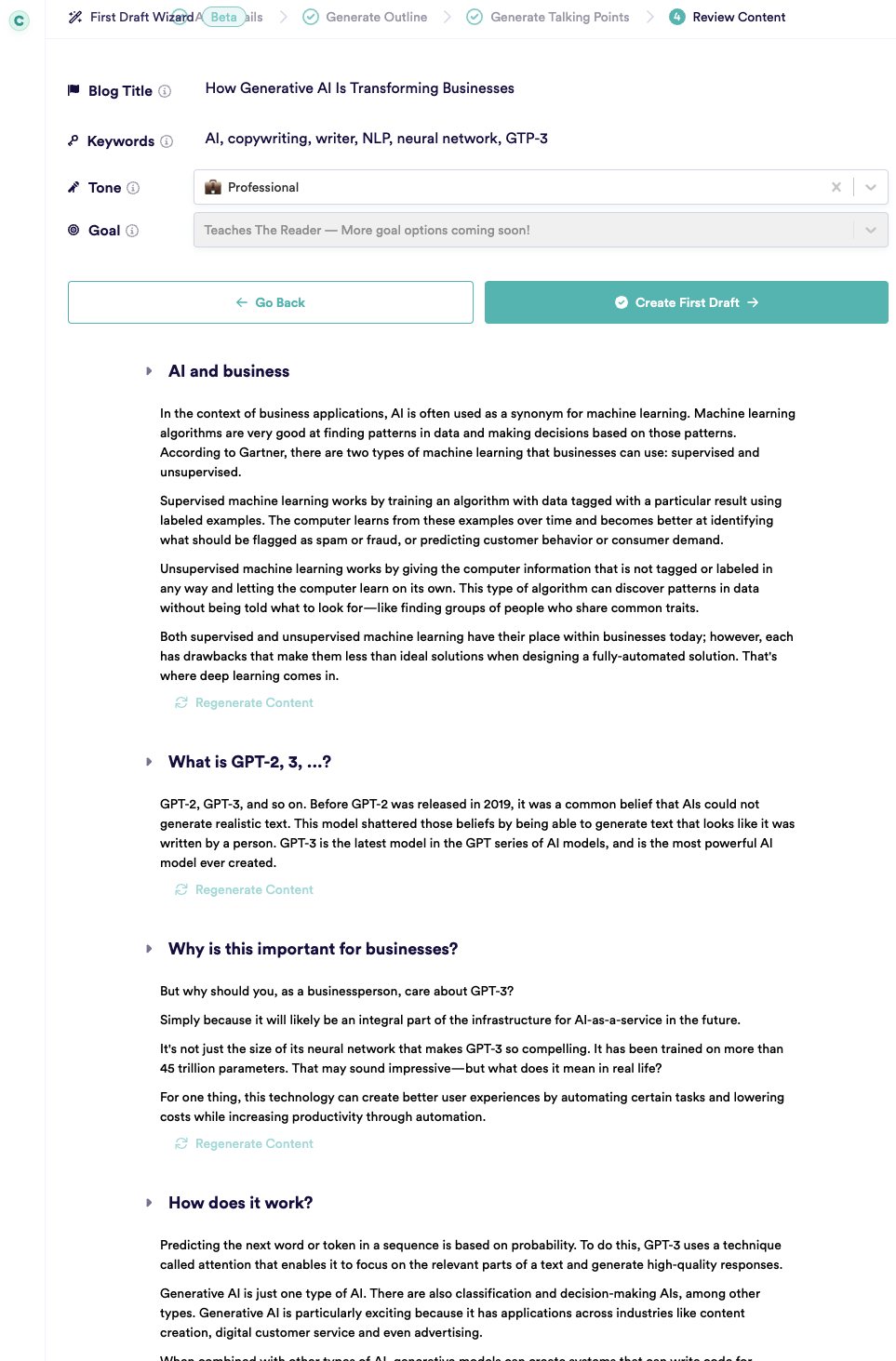
具体的には、まず記事タイトルとキーワードからアウトライン(大見出し数個と中見出し数個)を生成しました。次に、そのアウトラインを見ながら2箇所ほど「ここは違うテーマに変更」「このテーマを掘り下げる」と指示して部分的にアウトラインを再生成してみました。この作業は「変更すると、どんな内容に変わるだろうか?」という興味からやっただけで、何もしなくても結果に大差はありません。そして最後にブログ全文(英語)を生成して、それを無編集のままDeepLに入れました。翻訳された日本語のブログ記事は以下のとおりです。良く書けているところと異様なこじつけが混在する不思議な感じですが、驚くべきクオリティーと言って良いかと思います。

生成過程のUIは以下のような感じで、「Regenerate Content」をクリックすれば、どの段落も書き直しをさせることができます。
ちょっとテーマがニッチすぎましたが、例えば「快適な睡眠のための7つのアドバイス」と入力すれば、ものすごく普通に読めるブログ記事が生成されますし、よく見かけるタイトルを20個くらい生成してくれます。
「愛と猫」とキーワードを2つ与えて、何か比喩を作ってくれと指示すると「愛と猫は似ている。どちらも説明がつかない」などと、それっぽいコピーを10個くらい生成してくれます。
また、架空のスマートベッドの商品説明を生成してみたところ、ありきたりではあるものの、良く書けた紹介文が10個ほど瞬時に生成されました。YouTube動画の紹介文なども、入れたい情報を適当にタイプして生成するほうがゼロから自分で書くよりも手軽です。しかも、SNS投稿だと、自分では思いつかない絵文字や改行の使い方を示してくれたりします。
やや英語の直訳風ではあるものの、Copy.aiは入力、出力ともに日本語にも対応しています。「ビジネス変革に求められるリーダーの資質」などとタイトルを入れると、以下のように、そのまま使ってもおかしくないブログの結論が生成されました。
一般利用者に向けた文章生成AIサービスは、まだ黎明期であるものの、AI翻訳やAI文字起こし同様に、知的生産の補助ツールとしてはきわめて有用であるように思います。例えば、この章の最初の段落にあるCopy.aiの資金調達額や創業年などは、人間がネット検索してセンテンスとして整えるべき理由などありません。「copy.aiの調達概要」とでも入れてタブキーを押し、2、3文ほど自動生成してくれたら、ずいぶん楽になります。「投資家の名前を、もう1つくらい足して」と口頭で指示できれば有能な編集アシスタントになりますし、このとき「どのVCの名前を優先して出すべきか」という判断についても、業界の常識から判断してくれるようになる未来も、すぐそこに思えます。
Copy.aiの類似サービスとしてはShortlyAI,CopySmith、Conversation.ai、Content Villainなどがあります。
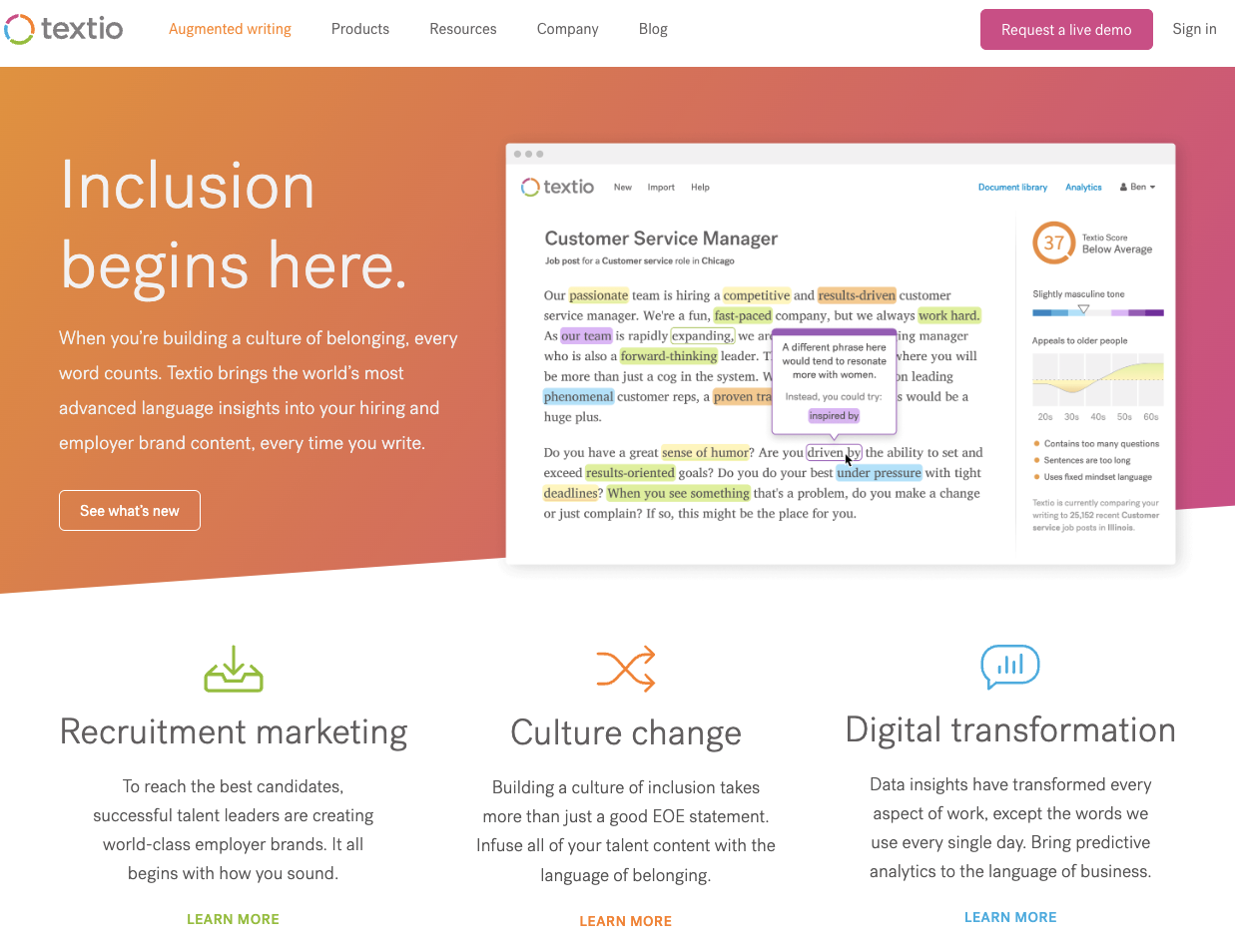
文法・文体チェックサービスとしてはGrammarlyがユニコーンとして有名ですが、同様のサービスとしてTextioも興味深いサービスです。Textioは企業が採用広告やジョブ・ディスクリプションを出すときに、文体をチェックして、より候補者をアトラクトできるワーディングを推奨してくれたり、無意識に紛れ込んだジェンダーバイアスを指摘してくれたりするサービスです。Textioは「augmented writing」という言い方をしていますが、こうした応用はほかにもまだまだ出てきそうです。
読むよりも、対話で知識を得る
ちょっと想像をふくらませると、Copy.aiのような技術は、何か新しい知識を得るときの対話型学習ツールにもなり得るのではないかと思えます。もう少し言えば知識伝達媒体として500年に及んだ「書物」「文書」の時代は終わり、対話型UIに進化するのではないか、とすら思えます。現在、テキストは動画に取って代わられつつありますが、どちらも今のところインタラクティブではないという点では変わりません。
例えばカント全集を読むよりも、カントのような口調で延々と対話してくれるアバターが出てきて彼の哲学を教えてくれたらいいと思いませんか? 画像・映像の生成コストも下がっていくことでしょうから、あたかも本人のようなデジタル・ビーイングと対話して直接師事することもできるようになるかもしれません。書店の、いわゆる実用書の棚などは対話型コンテンツのほうが良いのではないでしょうか。私はたくさん本を読み、文章を書くタイプですが、正直もう「読みたくない」とも思っています。知りたいだけなのです。
医師が患者に対して行う説明を動画として提供するスタートアップ、Contreaは病状や施術の説明を動画やアニメで行うプラットフォームを提供していますが、最新の大規模言語モデルの上に医療関係のドメイン知識を載せれば、かなり上手に質問に答える対話型サービスが作れるかもしれません。
企業のオンボーディングでも、一気に大量の文書やリンクを渡すより、どんな質問にでも回答するようなAIボットのほうが新メンバーには優しいかもしれません。このとき、特別に誰かが文書をまとめる必要はなく、既存の文書から学習したAIが、質問に適切に答えることができるはずです。例えば数年分の会議のメモが残っていれば「以前会議で決めたxの要点は何だっけ?」という質問にも議論の変遷を踏まえた上で、端的に回答してくれるAIサービスが作れそうです。
実際、こうしたことに近い応用は出てきています。GTP-3を使ったサービスは数百単位で出てきていて、例えばViableは蓄積されたECサイトのユーザーのフィードバックに対して「チェックアウトのプロセスで顧客は何を不満に感じてる?」と質問することで「画面切り替えが遅いこと。加えて、チェックアウト時に住所を編集できないこと、複数の支払い方法を保存できないことも」とスパッと集約した回答を出してくれるといいます。
Fable StudioはVR上でインタラクティブなストーリーを展開するコンテンツスタジオです。登場するキャラクターと自然な会話ができることで話題となりましたが、今は、そうしたキャラクターをユーザー自身が作成できるようにオーサリングツールを利用者に開放しています。与えられた世界で完結するだけでなく、そこに参加者たちが何かを作ることで世界を変えていくというメタバース的な世界観の事例としても興味深いところです。
リード・ホフマン創業のInflection.AIは究極のHMIを目指す?
LinkedIn共同創業者、またペイパルマフィアやFacebookへの初期投資家としても知られるリード・ホフマン氏は、2022年3月にDeepMind共同創業者でGoogleのVPだったムスタファ・シュリマン氏らとInflection.AIというスタートアップを創業しています。2016年にマイクロソフトへ$26.2bという巨額でLinkedInを売却して以来、はじめて創業するスタートアップということで注目を集めています。
今のところ、Inflection.AIは「人間がコンピューターと対話するのを簡単にするAIを開発する」としか言っておらず謎に包まれています。これまでコンピューターに何かをやってもらうためにはプログラミング言語を学んだり、コンピューターが理解できるマウス操作などを学ぶしかありませんでしたが、いずれ誰でも普通に話すだけで良くなる、と言っています。Inflextion.AIのシュリマンCEOは、今まさにコンピューターは人間レベルの言語生成が可能になろうとしていることを前提として「プロダクトの領域で、いろいろな新しいことができるチャンスが広がっている」としています。
「AIには創造性がない」「AIに知識や常識を教える試みは失敗したか、少なくともまだ見通しは立っていない」というクリシェは、もう過去のもの。現在起こっている大規模言語モデルの進化は「精度が上がりつつある」という漸進的なものではなく、時代を画するブレークスルーのように私には思えます。日本語圏のわれわれは、そして日本のスタートアップはどうするのか? という大きな問いはありますが、今後、革新的なスタートアップやサービスが日本からも登場するのではないかと考えています。
Partner @ Coral Capital





