
スタートアップの開発の失敗を赤裸々に語るライトニングトークに8社のCTOやエンジニア、プロダクトマネージャーが登壇。本記事では、株式会社Seibii エンジニアの辻天斗氏による「通知機能をマイクロサービス化していたらユーザ一斉通知でしくじった話」と題したトークの内容をお伝えします。
※本記事はCoral Capital出資先約80社からなるスタートアップコミュニティー「Coral Family」のうち、CTO・エンジニアが定期的に集まるCoral Developers。その中から生まれたイベント「スタートアップ開発しくじり先生LT」の発表を記事化したものです。

辻といいます。組織の規模がまだ小さいので、インフラ、バックエンド、フロントエンド、アプリ全般をやっています。
Seibiiは出張でクルマの整備・修理をするWebサービスです。店舗にお客さんが行くのではなく、お客様の自宅まで出張するところが既存の整備・修理と大きく違います。2019年1月に会社を設立し、累計で10億円ぐらい調達している企業です。
今回の話の前提として、Seibiiのバックエンドはどうなっているのかをお話します。メインの部分はモノリシックな作りで、Ruby on Railsで作ったseibii-apiに集約されています。通知の部分をRubyのHanamiというWebフレームワークを使用してnotificationというマイクロサービスにしています。
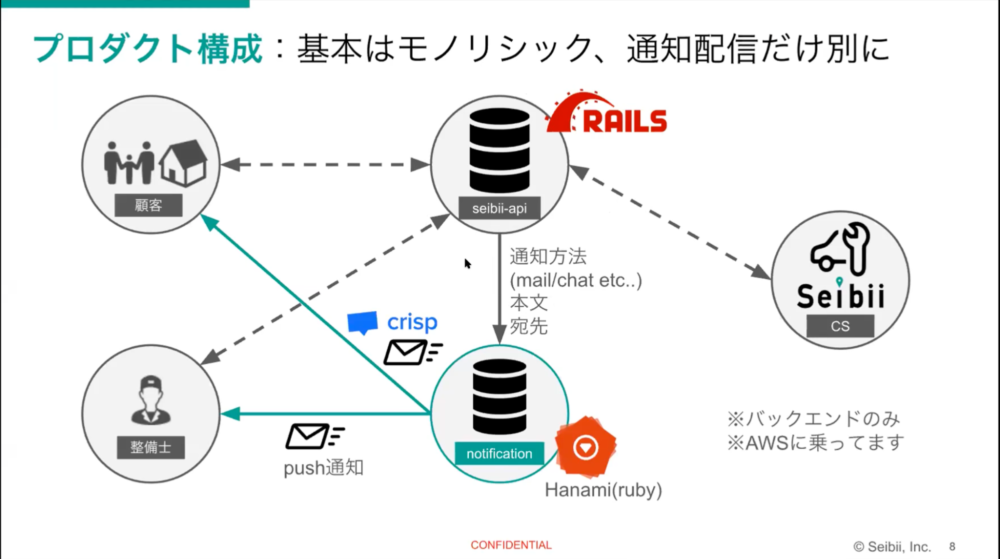
基本部分をモノリシックにしている理由は少人数での開発のスピードを上げるため。一方、通知をマイクロサービスに切り出した理由は、サービスが増えたときに通知部分は共通化したいし、通知機能は変更の可能性が少ないだろうというところです。
ある日のことです。「そろそろ稼働を始めようかな」と思って開始すると、同じ内容のメールが5件、手元に届いていました。朝から障害で「ぴえん」という感じです。とりあえず止血作業です。
メール送信ジョブを確認すると、未送信も含めて正常時の10倍以上の件数に膨れ上がっていました。これは早く止めないと。そこで本番通知DBの直操作で当該ジョブを消去しました。これですぐできる対応は取ったと思いました。ただし、対応後にも送信されているユーザー分については、メール送信に使っているsendgridのジョブにあって、当社側からでは制御できません。なんとか止めたいので調査を進めました。一方で、この頃は別件でデプロイできない問題も発生し、チーム全員で並行して対応を進めました。
なぜデプロイできなくなっていたのか。この時期、Railsでmimemagic GPL問題というものが起きていました。Railsで使っているライブラリmimemagicにGPLのファイルが混入し、過去のバージョンも消されて取得できなくなり、ビルドができなくなった時期がありました。その結果、当社の環境でもECS(Amazon Elastic Container Service)の本番コンテナやステージングコンテナをビルドできなくなっていました(この問題は「mimemagicの最新動向」にまとめられています)。このような事情もあり、障害の真因調査を先送りにしてしまっていました。
ところが、まだ通知が飛んできます。障害対応が終わっていないのかな、「ぴえん」を越えて「ぱおん」という状態です。別のエンジニアが素早く対応してくれました。「まさか、まだseibii-api側のjobが活きてる? Killしました」と連絡がきました。ここで使っていたライブラリSidekiqは、失敗したジョブを時間差で生き返らせて再試行するので、一回killすれば落ち着くのは幻想だ、というところを気をつけないといけないなと思ったところです。
障害の真因は、seibi-apiとnotificationとの間で結果の不整合が発生していたことでした。両者はhttpベースでやりとりしていますが、間にELB(Amazon Elastic Load Balancing)が入っていて、それがデフォルト値の60秒よりずいぶん短い値に設定されていました。レビュー時にこれに気がついていなかったことが問題でした。ここは反省点です。
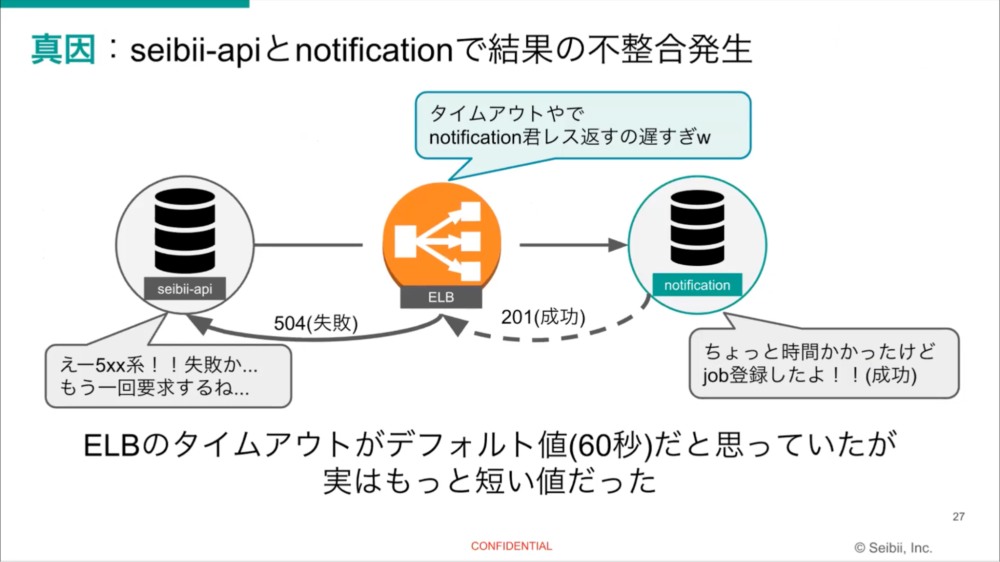
なぜ短い値になっていたのか。既存のELB設定コードをそのままコピペして問題のELBに貼り付けていて、想定と違う挙動になっていました。そのためnotification側では成功とみなしても、seibi-api側ではタイムアウトで失敗とみなして再要求を繰り返しており、同じ通知を大量に発生する障害を引き起こしてました教訓です。マイクロサービス化するときにはタイムアウトは長めに取りましょう。
教訓:障害の原因究明では根拠をはっきり言語化する
今回の反省です。障害発生で焦っているときこそ根拠を大切にしましょう。思いつきでプログラムの動きを推測して収束と思い込まない方がいいです。ソースコードやデータを示して、根拠を言語化して明示する形で進めましょう。
逆に、このような障害だからこそチームで対応したことが良かったと思っています。ここは継続したいところです。チームメンバ全員で調査・対応する項目を手分けして対応することで、見過ごしがあってもそれに気づける可能性が高まります。
(執筆:星 暁雄)
【スタートアップ開発しくじり先生のトークまとめ、全記事一覧】
Written by






